A canonical URL is a useful feature which you use to tell search engines the original source of a content on your website. If your website has the same content used across multiple pages, a canonical URL HTML element on a page can be used to tell search engines which page is the original source of the content and which page should be shown in search engine result pages.
Canonical URL greatly helps with duplicate content issues. If multiple pages on the same domain (or in different domains) have the same content in it, it is a violation of Google webmaster quality guidelines. However, if you use the canonical HTML element in all these pages and properly instruct search engines the original source page and the duplicate pages, search engines will understand that there is one page which is the original source of the content while other pages are duplicate copies and not to be shown in search engine result pages.
There are situations when your website may need the same content across multiple pages. For example, an eCommerce site may want to re-use some content or a portion of the content found on a page across multiple pages. It is possible that pages are generated dynamically or it is user-generated content, a forum post or any other type of page on your website which re-uses content from another page on the same website or another page on a different website. If there is absolutely no way to prevent this situation from happening, a canonical URL is especially helpful to avoid duplicate content issues with search engines and tell search engines that some pages of your website are re-using content from an “original source”.
In this article, we will learn more about Canonical URL’s and how to use them for search engine optimization of your website.
Example of Using Canonical URL’s
Let’s say you have a page on your website – www.example.com/shoes.html
You have another page on your website – www.example.com/footwear.html
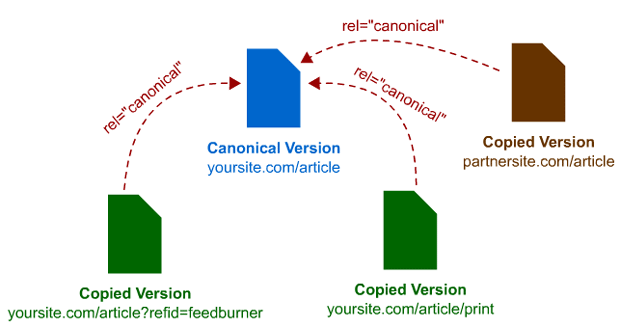
The second page is just a landing page which uses the same content from the “Shoes” page, but you have kept this page to do some A/B testing, land specific visitors from a marketing campaign or maybe even test out some PPC campaigns from Google Adwords. The content on the “Footwear” page is an exact replica of the “Shoes” page, the only difference is the presentation of content along with some cosmetic changes.
The Footwear page does not provide any additional value to users and is hosting duplicate content from the “Shoes” page. You do not want to delete the Footwear page from your website and neither do you want to 301 redirect the footwear page to the shoe page. You want to keep both the pages but not have any duplicate content or SEO issues because of duplicate pages hosting the same content on the same domain.
In this situation, it makes sense to use the canonical HTML element tag to tell search engines which one is the original source and which one is the duplicate source. To implement canonical URL’s for these two pages, you will need to do the following
Add the following code in the head section of the “Shoes” page, the page which hosts the original content and should be indexed by Google and shown in Google search result pages
<link rel="canonical" href="http://www.example.com/shoes.html">
Add the following code in the head section of the “Footwear” page, the page which hosts duplicate content and should not be indexed by Google and not shown in Google search result pages
<link rel="canonical" href="http://www.example.com/shoes.html">
So what you are actually doing is telling Google from both the pages which page is the original source. Once you have told Google the address of the page which is the original source, all the other pages which contain content from the original source will be automatically marked duplicate and now shown in Google search results. And since the pages which contain duplicate content have the canonical HTML element in them, your website will notbe penalized for duplicate content issues.
Please note that you could have also used Robots meta tags to noindex and nofollow the content and links in the duplicate page. But there is a subtle difference in using canonical tags versus the robots meta tag.
When you are using the Canonical meta tag, you are explicitly telling search engines which content is the original content and which one is duplicate content. This is considered a good practice when your website uses or re-purposes the same content across multiple pages. This practice keeps search engines aware that you are doing it for some unavoidable reasons but do not want to violate Google webmaster quality guidelines.
However, with the meta tags, you are not telling search engines which page is the original source and which page is the duplicate source which may cause issues with Google webmaster quality guidelines and your website may later be penalized for having too much duplicate content. It could be an algorithmic penalty like Google Panda, Google Penguin or a manual webspam action by Google Webspam team.
301 Re-direct or Canonical URLs?
There is a doubt among website owners whether they should 301 redirect the pages with duplicate content in them to the original source or use the canonical element in the duplicate pages.
If there is no practical reason to keep the duplicate pages on the website, you are better off deleting these pages and 301 redirecting the pages to the original source. That is the best approach.
However, if there is a reason to keep the duplicate pages on the website for user experience, marketing campaigns, split testing and other experiments, it is better not to 301 re-direct these pages to the original source but use the canonical element instead.
Canonical URL’s across Multiple Domains
Now, what if you have multiple websites which use the same content on selected pages? What if you re-purpose or syndicate content from other sites into yours? Should you use canonical URL’s if the content in question is being used by multiple domains which you may own or not own?
The answer is Yes, you should use canonical URL’s even if the content in question is being used from another domain which you own or not own. For example, if you are re-publishing an article from New York times website with explicit permission or re-publishing, you can mention at the top of the article that this article was originally posted on New York Times. Additionally, you can use the rel=canonical HTML tag to tell search engines that New York Times is the original source and you have copied the content from that website into your website for some reason.
If you don’t use the rel=canonical tag, it is not the case that search engines will not be able to figure out which one is the original source and which one is the duplicate one. But when you explicitly tell search engines that yours is not the original source, you prevent your website from being flagged by Google webspam team.
In short, canonical URL’s work exactly the same across multiple domains as they work in one domain, there is no difference in concept and execution.
If you are using WordPress as the content management system, you can use Yoast WordPress SEO plugin which automatically adds the rel canonical element in all the posts and pages of your website.
Be Sure to read our SEO Guide which contains useful information about SEO and we have discussed in detail key SEO Concepts with examples